






Testen im Zeitalter von KI

KI-basierte Systeme finden heute schon einen breiten Einsatz. Dies wird sich in der nahen Zukunft noch verstärken: Was wäre Smart Mobility ohne automatisiertes Fahren oder Industrie 4.0 ohne Predictive Maintenance? Hierbei lassen sich klassische Ansätze der Qualitätssicherung nicht mehr so einfach übertragen und ein Paradigmenwechsel wird notwendig. In diesem Artikel wollen wir daher auf Ansätze zur Qualitätssicherung von KI-basierten Systemen eingehen. Unser Fokus liegt dabei auf datengetriebenen Modellen, also Modellen, deren Ein-Ausgabe-Beziehungen automatisiert aus vorhandenen Daten, beispielsweise mittels Maschinellen Lernens, gewonnen wurden. Durch die Verwendung von solchen – letztlich unterspezifizierten – Komponenten wird es immer schwieriger zu garantieren, dass alle möglichen Fehlverhalten hinreichend unwahrscheinlich sind. Um Qualitätsziele während der Entwicklung trotzdem nicht aus den Augen zu verlieren und argumentativ belegen zu können, bieten sich so genannte Assurance Cases an, die systematisch Evidenzen, wie sie beispielsweise durch statistisches Testen entstehen, in eine schlüssige Argumentation integrieren.
An einem praktischen Anwendungsbeispiel stellen wir acht typische Herausforderungen und Empfehlungen bei der Erstellung eines entsprechenden Assurance Cases vor. Letztlich verlangt die erfolgreiche Absicherung eines spezifischen KI-basierten Systems jedoch ein hohes Maß an Interdisziplinarität, denn Kompetenzen aus den Bereichen Safety Engineering, Empirie und Machine Learning sowie aus der Anwendungsdomäne müssen zusammenkommen.
Motivation
Einsatz von KI wächst zunehmend
Die digitale Transformation ermöglicht digitale Produkte/Dienste, digitale Vertriebswege und digitale Geschäftsmodelle. Systemgrenzen verschwimmen zunehmend und digitale Ökosysteme entstehen. Dies ist kein vereinzelter Trend, sondert findet sich in fast allen Domänen und Anwendungsgebieten: von Smart Mobility über Smart Farming bis hin zu Smart Production, in Deutschland als Industrie 4.0 bekannt. Die damit einhergehende Verschränkung von eingebetteten Systemen und klassischen Informationssystemen erhöht die Komplexität der Systeme oder besser der Systems of Systems signifikant und stellt die Sicherung der Systemqualität vor Herausforderungen.
Im Bereich Software- und Systems-Engineering sind wir mit dem Problem der steigenden Systemkomplexität schon seit längerem vertraut. Hier gibt es Verfahren zur Qualitätssicherung und insbesondere Testverfahren, die entsprechend skalieren und keinen grundsätzlichen Paradigmenwechsel erfordern. Viele neue digitale Produkte und Dienste basieren aber auf Daten oder Modellen, die aus Daten abgeleitet werden. Beim Bau dieser Modelle zur algorithmischen Entscheidungsfindung setzt man zunehmend auf Verfahren der Künstlichen Intelligenz (KI). Hier lassen sich klassische Ansätze der Qualitätssicherung nicht mehr so einfach übertragen und ein Paradigmenwechsel wird notwendig.
Der Begriff KI ist zunächst einmal recht schwammig und bezeichnet eher eine Obergruppe von Ansätzen, die versuchen, intelligentes Verhalten zu automatisieren, also in Algorithmen zu gießen. Die KI-Forschung ist auch kein wirklich neues Feld. Ihre Anfänge gehen auf die frühen 1950er Jahre zurück. Populäre Ansätze sind aktuell insbesondere das Maschinelle Lernen und dort vor allem das Teilgebiet des Deep Learning, in welchem mehrschichtige Künstliche Neuronale Netze (KNN) zur Entscheidungsfindung erstellt werden. Die Popularität resultiert insbesondere aus der im letzten Jahrzehnt erzielten Verbesserung der Genauigkeit (z. B. durch immer größere Mengen an verfügbaren Daten), aber auch aus einem deutlichen Performanzzuwachs im Hardwarebereich (z. B. durch den Einsatz von GPUs) und effizienteren Lernverfahren.
KI-basierte Systeme finden heute schon einen breiten Einsatz, wenn es um das Verständnis/Profiling von Nutzern, die Bilderkennung oder Spracherkennung, -übersetzung und -synthese geht. Sie bilden die Basis intelligenter Ökosysteme: Was wäre Smart Mobility ohne automatisiertes Fahren oder Industrie 4.0 ohne Predictive Maintenance, also die vorausschauende Wartung von Maschinen und Produktionsanalagen? Auch wenn KI-basierte Systeme teilweise ihren praktischen Nutzen jenseits der heute schon existierenden Einsatzzwecke noch unter Beweis stellen müssen, so reicht das Versprechen ihrer Vielseitigkeit kombiniert mit der (vermeintlich) einfachen technischen Umsetzung mittels Open-Source-Softwarekomponenten und preisgünstiger Hardware aus, um die diskutierten Einsatzmöglichkeiten rasant ansteigen zu lassen.
Qualitätssicherung bei KI-basierten Systemen
In diesem Artikel wollen wir uns damit beschäftigen, wie KI-basierte Systeme qualitätsgesichert werden können. Unser Fokus liegt dabei auf datengetriebenen Modellen, also Modellen, deren Ein-Ausgabe-Beziehung automatisiert aus Daten, beispielsweise mittels Maschinellen Lernens, abgeleitet werden.
Qualitätssicherung und insbesondere Testen spielt im Kontext datengetriebener Modelle eine besonders wichtige Rolle, um Vertrauen in das Modell selbst zu gewinnen, aber auch in das System, in welchem das Modell ausgeführt wird. Vertrauen heißt in diesem Zusammenhang nicht nur, dass das System keine Gefahr für Leib und Leben darstellt und (weitgehend) fehlerfrei funktioniert, sondern dass es – je nach Anwendungszweck – eine Reihe weiterer Qualitäten erfüllt, wie beispielsweise, dass Entscheidungen bezüglich gewisser Aspekte diskriminierungsfrei sind.
In einem klassischen softwarebasierten System wird die Funktionalität durch die Entwickler über Befehle vorgegeben, die eine bestimmte Eingabe eindeutig in eine Ausgabe überführen. Testen konzentriert sich dann darauf, die Zuverlässigkeit des Systems zu untersuchen, indem anhand von Testfällen geprüft wird, ob die spezifizierten Befehle Eingaben in die erwarteten Ausgaben überführen.
Bei datengetriebenen Komponenten hingegen wird die Funktionalität nicht durch Befehle vorgegeben, sondern durch ein (hochgradig) parametrisiertes Modell bereitgestellt, dessen Parameter mittels eines vorgegebenen Lernverfahrens automatisiert bestimmt werden [1].
So haben aktuelle Künstliche Neuronale Netze aus dem Bereich des Deep Learning gewöhnlich mehrere Millionen Parameter, die automatisiert angelernt werden, um beispielsweise Objekte wie Straßenschilder oder Personen in Bilddaten zu erkennen.
Dabei unterscheidet man grundlegend zumindest zwischen Trainingsdaten, mit denen das Modell angelernt wird, und Testdaten, mit denen geprüft wird, wie gut das Modell arbeitet. Die Zuverlässigkeit der Modellausgaben hängt hierbei unter anderem von der Art des Modells und des eingesetzten Lernverfahrens ab, aber auch von den Daten, welche genutzt wurden, um das Modell zu trainieren. So können diese beispielsweise Qualitätsdefizite aufweisen (z. B. nicht die Realität abbilden, Inkonsistenzen aufweisen oder den intendierten Anwendungskontext nicht ausreichend abdecken).
Klassisches Testen setzt typischerweise eine detaillierte Spezifikation der Komponenten voraus, um daraus Testfälle abzuleiten und angemessenes Systemverhalten sicherzustellen. Das Problem bei KI-basierten Komponenten liegt darin, dass die Spezifikation nicht für jede konkrete Eingabe festlegt, welche Ausgabe gewünscht ist, sondern dass basierend auf Daten ein Modell gelernt wird. Diese Daten stellen allerdings lediglich einen Ausschnitt möglicher Eingaben und erwarteter Ausgaben dar. Für den Rest der Eingaben gibt es keine klare Spezifikation und daher auch kein Test-Orakel, aus dem geeignete Testfälle abgeleitet werden könnten.
Assurance Cases als Mittel der Wahl
Durch die steigende Komplexität der Systeme und die Verwendung von ML-Komponenten wird es immer schwieriger zu garantieren, dass alle möglichen Fehlverhalten hinreichend unwahrscheinlich sind. Der Zusammenhang zwischen Qualitätssicherungsmaßnahmen wie Testen und dem Qualitätsziel wird immer komplizierter. Um das Qualitätsziel während der Entwicklung nicht aus den Augen zu verlieren und nach der Entwicklung argumentativ belegen zu können, warum es erfüllt wurde, bieten sich Assurance Cases an. Ein Assurance Cases erklärt stichhaltig, warum ein bestimmtes Ziel erreicht wurde. Assurance Cases sind insbesondere in der Sicherheitstechnik weit verbreitet und gewinnen dort zunehmend an Bedeutung, wenn es darum geht, darzulegen, warum ein System mit kritischen ML-Komponenten sicher ist.
Für besonders wichtige Qualitätsziele wie beispielsweise Sicherheitsziele sollte man einen Assurance Case aufstellen und erklären, wie die Qualitätssicherungsmaßnahmen zum Erreichen des Ziels beitragen und warum sie ausreichen. Beim Testen von ML-Komponenten wirft dies dann folgende fundamentale Frage auf: "Welche Aussagekraft hat das Testen für mein Qualitätsziel?". Bei "normal" programmierten Komponenten liefert systematisches Testen Indizien dafür, dass kein grundlegender Denkfehler beim Aufstellen der kausalen Zusammenhänge zwischen Eingabe und Ausgabe gemacht wurde und dass die Zusammenhänge auch korrekt im Code umgesetzt wurden. Welche Aussagekraft hat aber das Testen, wenn die Kausalitäten in einer Spezifikation durch Korrelationen zwischen Daten ersetzt werden?
Im Folgenden wollen wir auf diese und andere Fragen eingehen. Wir zeigen beispielhaft auf, wie man das Testen von ML-Komponenten als Teil der Qualitätssicherung in einen Assurance Case mit einfließen lassen kann.

Assurance-Case-Einmaleins
Assurance Cases erklären in einer auf Nachweisen basierenden Argumentation, warum eine bestimmte Behauptung gilt. Die Argumentation bricht die Behauptung auf andere Behauptungen herunter, die dann durch Nachweise belegt werden. Abb. 1 veranschaulicht dies anhand eines Induktionsbeweises. Die initiale Behauptung wird durch einen Ableitungsschritt in zwei Behauptungen zerlegt. In der Regel hat die Argumentation aber mehrere Ableitungsschritte. Wie im rechten Teil der Abb. 1 dargestellt, ergibt sich dadurch eine baumartige Struktur.

Es gibt verschiedene Modellierungssprachen, um Assurance Cases und die baumartige Argumentationsstruktur grafisch darzustellen. Zu den bekanntesten gehören die Goal Structuring Notation (GSN) [2] und die Claims Arguments Evidence (CAE) Notation [3]. Sie unterscheiden sich mit Ausnahme der Namen der Modellierungselemente nicht wesentlich. Bei der GSN passt die Namensgebung eher zu einer Top-down-Zieldekomposition. Bei der CAE Notation passt sie eher zu einer Bottom-up-Schlussfolgerung. Für die praktische Anwendung spielt dies aber keine Rolle, da eine Argumentation normalerweise inkrementell sowohl top-down als auch bottom-up aufgebaut wird. Top-down versucht man die Qualitätsziele auf Vorgaben für Entwicklungsaktivitäten wie das Testen abzubilden. Bottom-up versucht man die Ergebnisse der Entwicklungsaktivitäten in die Argumentation einfließen zu lassen. Das gemeinsame Metamodell der Modellierungssprachen ist von der Object Management Group (OMG) standardisiert und heißt Structured Assurance Case Metamodel (SACM)[4].
Die grafische Darstellung macht die Argumentation übersichtlicher und einfacher anzupassen als eine lineare Argumentationskette in einem Textdokument. Die explizite Darstellung jedes einzelnen Ableitungsschritts ermöglicht eine systematische Überprüfung. Hierbei wird top-down geprüft, ob die abgeleiteten Behauptungen vollständig sind, und bottom-up, ob die abgeleitete Behauptung wirklich impliziert wird.
Anwendungsbeispiel

In Abb. 2 skizzieren wir den Aufbau eines Assurance Cases mit Fokus auf dem Testen von KI-Komponenten. Wir betrachten dazu ein optisches Warnsystem bei Erdbaumaschinen (wie Bagger oder Raupen) als Anwendungsbeispiel.
Das System dient der Warnung eines Fahrers vor Personen im toten Winkel des Fahrzeugs. Durch die Überarbeitung der ISO 5006 [5] können die meisten Erdbaumaschinen die geltenden Anforderungen ohne ein (ML-basiertes) Kamera-Monitor-System (KMS) nicht erfüllen und müssen deshalb nachgerüstet werden [6].
Der Assurance Case in Abb. 2 skizziert eine Argumentation für die Behauptung "Der Fahrer wird in seiner Arbeitsumgebung vor (wahrnehmbaren) Personen im toten Winkel hinreichend zuverlässig gewarnt".
Im Folgenden greifen wir uns einzelne wichtige Aspekte dieser Argumentation heraus, diskutieren acht typische Herausforderungen und geben Empfehlungen in Bezug auf das statistische Testen der ML-Komponente.
Herausforderungen und Empfehlungen
1. Zielformulierung und Trade-offs
Betrachten wir das Qualitätsziel "Der Fahrer wird in der Arbeitsumgebung vor wahrnehmbaren Personen im toten Winkel hinreichend zuverlässig gewarnt". Das "hinreichend zuverlässig" adressiert fehlende Warnungen ("falsch negativ"), diese stehen aber in einer Beziehung zu den ebenfalls ungewollten Fehlalarmen ("falsch positiv"). Die Fehlerbilder und ihre Minimierung stehen im Konflikt miteinander. Plastisch wird dieser Konflikt am Extrembeispiel, in welchem dem Fahrer während der Nutzung einfach konstant eine Warnung angezeigt wird.

Empfehlung: Die Argumentation muss also erklären, wie dieser Konflikt aufgelöst und die initial abstrakten Ziele in konkrete, aber nicht widersprüchliche Anforderungen heruntergebrochen werden. Weiterhin muss sie darlegen, warum die Fehlerwahrscheinlichkeiten "hinreichend niedrig" sind (unter Berücksichtigung des realistisch Möglichen), denn eine Restwahrscheinlichkeit wird es aufgrund zufälliger Fehler immer geben. Ein Qualitätsziel sollte daher auch keine absoluten Vorgaben mit Wörtern wie "immer" oder "niemals" machen, denn diese sind per se in diesem Kontext nicht erfüllbar.
2. Funktionale Dekomposition bezüglich KI
In den meisten Fällen hat es sich bewährt, das Ziel zunächst schrittweise gemäß den Aufgaben zu zerlegen, die für die Zielerreichung notwendig sind. Beispielsweise kann das zuvor genannte Ziel in die Ziele (1) "Wahrnehmbare Personen im toten Winkel werden hinreichend zuverlässig in der Arbeitsumgebung erkannt" und (2) "Warnung wird an den Fahrer ausgegeben, wenn eine Person erkannt wurde" zerlegt werden.
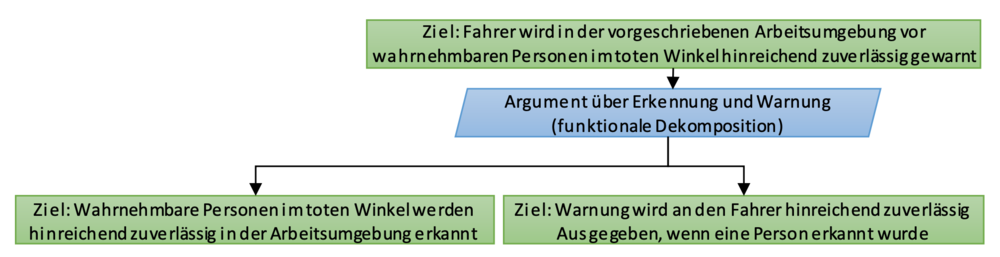
Ein Abbruchkriterium für die weitere funktionale Dekomposition ist dabei eine Ebene, auf der Aufgaben eindeutig konkreten Komponenten zuordnet werden können. So lässt sich das linke Ziel einer datengetriebenen Komponente im System zuordnen, wohingegen das rechte Ziel mit klassischen Hardware- und Softwarekomponenten zu realisieren ist, zu deren Absicherung etablierte Standards existieren und auf die wir daher hier nicht weiter eingehen werden.
Empfehlung: Eine Dekomposition sollte zunächst funktional bis auf die Ebene konkreter Komponenten erfolgen.
3. Dekomposition bezüglich notwendiger Zuverlässigkeit
Datengetriebene Komponenten erfüllen ihre Aufgabe normalerweise nicht in jeder Situation mit dem gleichen Grad an Zuverlässigkeit [7]. Die Zuverlässigkeit einer Objekterkennung hängt beispielsweise unter anderem von den vorliegenden Lichtverhältnissen ab. Es gibt also bestimmte Situationen, beispielsweise bei starker Dunkelheit, bei denen man sich weniger auf die Korrektheit einer Ausgabe verlassen kann. Ebenso gibt es bestimmte Situationen, bei denen wir geringere Anforderungen an die Zuverlässigkeit haben. Dies sind Situationen, die weniger riskant sind oder in denen eine höhere Risikoakzeptanz unterstellt werden kann. Bezogen auf unser Beispiel kann man sich vorstellen, dass alle Personen in der Arbeitsumgebung verpflichtet sind, Schutzkleidung zu tragen, und es daher als akzeptabel angesehen werden kann, wenn Personen ohne Schutzkleidung weniger zuverlässig erkannt werden.
Der Assurance Case muss erklären, warum die Ausgabe für alle Eingabebereiche hinreichend zuverlässig ist. Das legt eine Einteilung der Eingabebereiche und eine entsprechende Fallunterscheidung im Assurance Case nahe. Zunächst sollte dabei bezüglich der geforderten Zuverlässigkeit unterschieden werden. Folgende Dekomposition veranschaulicht dies am Beispiel.
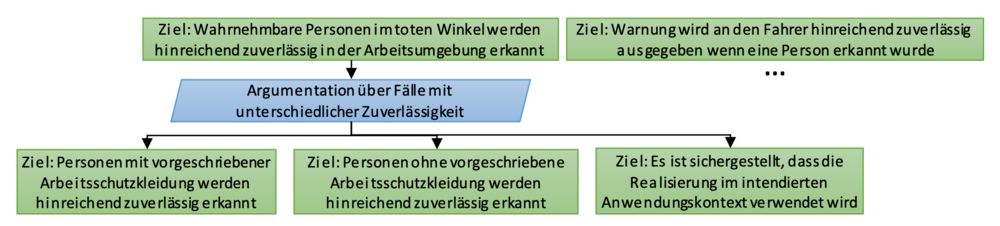
Es gibt hierbei verschiedene denkbare Argumente für unterschiedliche Grade an Zuverlässigkeit. Das Risiko ist eine Kombination aus der Wahrscheinlichkeit (1) der Situation, (2) einer ausbleibenden Warnung in der Situation, (3) dem Risiko, dass es bei ausbleibender Warnung zu einem Unfall kommt und (43) der Schwere eines solchen Unfalls. Die Wahrscheinlichkeit der Situation beeinflusst also das resultierende Risiko. Entsprechend könnte man der Argumentation folgen, dass das System im Fall fehlender Schutzkleidung nicht so zuverlässig sein muss, da der Fall sehr selten auftritt. Es ist auch denkbar, ein Eigenverschulden einer Person beziehungsweise einen Regelverstoß mit in die Argumentation einfließen zu lassen. Natürlich darf man nicht unnötig viele Fälle konstruieren und anschließend argumentieren, dass jeder einzelne Fall hinreichend unwahrscheinlich ist.
Empfehlung: Eine Dekomposition sollte anhand von Zuverlässigkeitsanforderungen erfolgen, die sich aus unterscheidbaren Risikoklassen bzw. Risikoakzeptanzniveaus begründen.
4. Scope Compliance
Die Fallunterscheidung muss zudem vollständig sein und es darf kein Fall vergessen werden. Eine lückenlose Zerlegung und realistische Risikoabschätzung sind jedoch nur dann möglich, wenn wir Annahmen über den Anwendungsbereich machen [8]. So wird in der beispielhaften Zerlegung die Annahme gemacht, dass alle Personen Schutzkleidung tragen müssen. Diese Annahme ist aber nur haltbar, wenn wir die "vorgeschriebene Arbeitsumgebung" klar definieren (z. B. vorschriftsmäßig abgesicherte Baustellen in der EU) und Situationen zuverlässig verhindert oder erkannt werden, in denen das System außerhalb des Anwendungsbereiches operieren würde. So wird in unserem Beispiel im Rahmen eines dritten Ziels explizit gefordert, "dass die Realisierung im intendierten Anwendungskontext verwendet wird."
Empfehlung: Der intendierte Anwendungsbereich muss klar definiert und eine "missbräuchliche" Verwendung sollte entsprechend verhindert oder zumindest detektiert werden können.
5. Quantifizierung der notwendigen Zuverlässigkeit
Bei der Dekomposition der notwendigen Zuverlässigkeit kann die Fallunterscheidung auf den höheren Zielebenen noch rein qualitativ erfolgen, ohne die unterschiedlichen Anforderungen bezüglich der Zuverlässigkeit zu quantifizieren. Eine Quantifizierung wird aber spätestens dann erforderlich, wenn man systematisch ableiten möchte, wie viele Testfälle benötigt werden und wie viele der Tests erfolgreich sein müssen.
Es ist allerdings nicht üblich, quantitative Zuverlässigkeitsanforderungen an Softwarekomponenten zu stellen. Wenn ein Fehler beim Black-Box-Testen von sicherheitskritischer Software gefunden wird, dann muss dieser beseitigt werden. Die Kritikalität gibt daher vor, welche Testmethoden angewendet werden sollen, aber nicht, wie viel Prozent der Testfälle bestanden werden müssen. Fehlerraten gibt es nur für zufällige Hardwarefehler. Diese sind aber so gering, dass entsprechende Anforderungen an eine datengetriebene Komponente nicht erfüllbar wären.
Trotzdem lassen sich valide Argumente für den Einsatz von datengetriebenen Komponenten in sicherheitskritischen Bereichen finden. Der Einsatz kann beispielsweise dann begründet werden, wenn die datengetriebene Komponente eine Funktion ermöglicht, die das System insgesamt sicherer macht. So kann beispielsweise die Tatsache, dass ein "Notbremsassistent" auf dem aktuellen Stand der Technik nicht jede Kollision verhindern kann, kein valides Sicherheitsargument dafür sein, keinen "Notbremsassistenten" in Fahrzeugen zu verbauen.
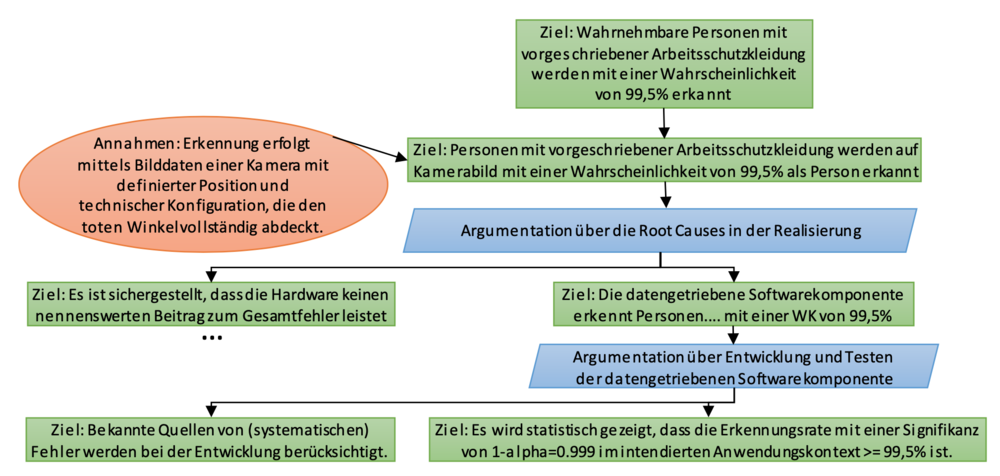
Empfehlung: Bei datengetriebenen Komponenten bietet es sich (im Gegensatz zu klassischer Software) an, die Zuverlässigkeit mittels Fehlerraten bzw. Wahrscheinlichkeiten zu quantifizieren.
6. Fehlerquellen bei der Realisierung datengetriebener Komponenten
Nachdem die Ziele für eine datengetriebene Komponente quantifiziert wurden, muss geprüft werden, was dies für die unterschiedlichen Bestandteile der Komponente bei ihrer Realisierung bedeutet. Klassischerweise wird hierbei zwischen Software- und Hardwarebestandteilen unterschieden. Bei konventionellen Komponenten wird gewöhnlich davon ausgegangen, dass Hardware eine abschätzbare Wahrscheinlichkeit für Fehler besitzt, wohingegen Software nur systematische Fehler enthält, die durch die Einhaltung bestimmter Praktiken in der Entwicklung hinreichend reduziert werden müssen.
Für datengetriebene Komponenten stellt sich diese Betrachtungsweise jedoch als eher weniger zielführend dar. Da sich schon die Anforderungen an die Funktionalität der Komponente nicht vollständig spezifizieren lassen, kann schwerlich ein Nachweis geführt werden, dass die Software der Komponente in allen Situationen wie intendiert funktioniert. Wie sollte beispielsweise für eine beliebige Kombination von Pixeln spezifiziert werden, ob diese eine Person darstellen oder nicht? Daher lassen sich sinnvolle Anforderungen an die Korrektheit einer datengetriebenen Komponente auch ausschließlich probabilistisch formulieren und entsprechend nachweisen. Hierbei erreichen Modelle auf dem aktuellen Stand der Technik Fehlerraten, die sich häufig in der Größenordnung von 10-2 bis 10-4 bewegen.
Hardwarebasierte Fehler, wie sie beispielsweise durch einen Bit-Flip im Speicher eines Steuergeräts auftreten können, sind hingegen um Größenordnungen seltener und führen noch viel seltener zu einer tatsächlichen Verfälschung der Ausgaben datengetriebener Komponenten. Da sich die Gesamtfehlerrate einer Komponente jedoch vereinfacht aus der Addition der hardwarebasierten und softwarebasierten Fehler ergibt, können die Auswirkungen hardwarebasierter Fehler im Vergleich zu den Fehlerraten der eingesetzten datengetriebenen Modelle häufig vernachlässigt werden.
Empfehlung: Bei der Abschätzung müssen sowohl software- als auch hardwareverursachte Fehlverhalten berücksichtigt werden, wobei letztere – Stand heute – größenordnungsmäßig jedoch meist vernachlässigbar sind.
7. Entwicklung und Testen von Software für datengetriebene Komponenten
Die Aktivitäten bei der softwareseitigen Realisierung einer datengetriebenen Komponente können grob in Entwicklung und Qualitätssicherung eingeteilt werden. Die Entwicklung umfasst dabei insbesondere (1) die Datensichtung und -aufbereitung sowie (2) die Modellbildung mit Auswahl passender Lernverfahren, Modellstrukturen und Hyperparameter sowie dem automatisierten Erlernen der Modellparameter. Aktuelle Vorgehensweisen sind hierbei meist hochgradig iterativ, geprägt von Intuition, Experimenten sowie hochspezialisiertem Erfahrungswissen. Im Vergleich zur klassischen Softwareentwicklung bestehen bis dato keine etablierten Prozesse und Praktiken, die nachweislich mit hoher Sicherheit zu zuverlässigen Realisierungen führen.
Obwohl inzwischen intensiv an Qualitätssicherungstechniken im ML-Bereich geforscht wird [9], ist die Menge etablierter Ansätze überschaubar. Viele im Bereich der Softwareentwicklung eingesetzten Techniken lassen sich bisher nicht einfach auf die Entwicklung datenbasierter Modelle übertragen. Beispielsweise erscheinen klassische Codereviews oder statische Codeanalysen wenig hilfreich. Auch grundlegende Ansätze im Bereich klassischer Softwaretests wie Äquivalenzkassenbildung oder die Ausrichtung der Testfälle anhand bestimmter Codeüberdeckungskriterien sind entweder nicht praktikabel oder bezüglich ihres Nutzens äußerst fraglich. Als anerkanntes Qualitätssicherungsverfahren kann hingegen das statistische Testen betrachtet werden, das insbesondere verwendet werden kann, um Ziele wie "es wird statistisch gezeigt, dass die Erkennungsrate mit einer Signifikanz von 0,999 im intendierten Anwendungskontext größer oder gleich 99,5 Prozent ist" mit Evidenzen zu belegen.
Empfehlung: Eine Argumentation, die sich ausschließlich auf die Anwendung etablierter Entwicklungsprozesse und Methoden beruft, erscheint für datengetriebene Komponenten bisher wenig zielführend und sollte vermieden werden. Eine inhaltliche Argumentation, die sich auf Ergebnisse des statistischen Testens stützt, sollte das Rückgrat des Assurance Cases bilden.
8. Zuverlässigkeitsargumentation über statistisches Testen
Die Argumentation bezüglich der softwareseitigen Zuverlässigkeit einer datengetriebenen Komponente kann sich beispielsweise auf drei Säulen verteilen. In der ersten Säule ist sicherzustellen, dass die beim Testen verwendeten Daten eine repräsentative Auswahl von Fällen aus dem intendierten Anwendungskontext darstellen. Dies hat insbesondere wichtige Implikationen für die Datenerhebung. In unserem Beispiel sollten Testbilder beispielsweise mit einer vergleichbaren Kamera an der intendierten Position auf verschiedenen zufällig ausgewählten europäischen Baustellen gesammelt werden. Daten von ausschließlich einer Baustelle oder Daten aus den USA wären hingegen offensichtlich nicht repräsentativ und die Testergebnisse damit nicht aussagekräftig. Ein eklatanter Fehler wäre auch, die Testdaten schon während der Modellerstellung zum Lernen der Modellparameter einzusetzen, denn auch dann hätten Testergebnisse auf Basis dieser Daten keine statische Aussagekraft mehr. Die notwendige Breite des Testdatensatzes hängt insbesondere von der natürlichen Varianz im Anwendungsumfeld und der relativen Häufigkeit relevanter Ereignisse ab. Hierbei kann es durchaus sinnvoll sein, seltene, aber risikoreiche Fälle überproportional zu ihrer tatsächlichen Häufigkeit im Testdatensatz zu berücksichtigen und die Testergebnisse anschließend mittels Gewichtung auf eine repräsentative Verteilung zurückzuführen.
Die zweite Säule der Argumentation beim statistischen Testen beruht auf der Annahme, dass die Testfälle korrekt sind, d. h. dass die Grundwahrheit (engl. ground truth) zuverlässig bestimmt wurde. In unserem Beispiel ergibt sich so das Ziel: "Alle Fälle von optisch wahrnehmbaren Personen mit vorgeschriebener Arbeitsschutzkleidung sind in den Testdaten als solche gekennzeichnet." Auch hierbei ergeben sich potenziell semantische Unklarheiten und mögliche Fehlerquellen. So ist zu klären, wann eine Person als optisch wahrnehmbar gilt, wie sichergestellt wird, dass optisch wahrnehmbare Personen mit hinreichend hoher Wahrscheinlichkeit auf den Bilddaten im Testdatensatz auch vermerkt sind, und wie dies kosteneffizient erfolgen kann. Derzeit ist die Erstellung qualitativ hochwertiger Testdaten noch immer eine mit hohem manuellem Aufwand und hohen Kosten verbundene Tätigkeit.
Die dritte Säule der Argumentation beim statistischen Testen bildet die Interpretation der Testergebnisse, wobei zu berücksichtigen ist, dass der Testdatensatz nur einen Auszug (engl. sample) aus dem intendierten Anwendungskontext darstellt. Daher kann eine Aussage zur Zuverlässigkeit im Anwendungskontext auf Basis der Testergebnisse nur bei Akzeptanz einer Irrtumswahrscheinlichkeit Alpha erfolgen. Diese bestimmt die Signifikanz der Aussage, die auf Basis der Testergebnisse bezüglich der Zuverlässigkeit getroffen wird [7]. Ohne die Angabe einer Irrtumswahrscheinlichkeit bzw. Signifikanz des Tests sind hingegen Informationen hinsichtlich der Zuverlässigkeit/Erkennungsrate nicht valide zu interpretieren. Dies mag das folgende Extrembeispiel illustrieren: Die Komponente wird auf einem Testdatensatz mit genau einem zufälligen Testfall aus dem Anwendungskontext geprüft und liefert für diesen ein korrektes Ergebnis. Daraus jedoch zu folgern, dass die Komponente im Anwendungskontext eine hundertprozentige Zuverlässigkeit aufweist, wäre offensichtlich fatal.
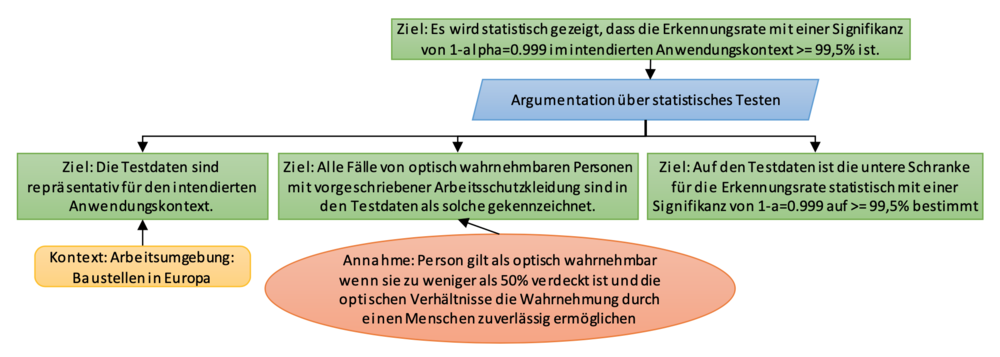
Empfehlungen: Erstens muss die Repräsentativität der verwendeten Testdaten sichergestellt werden können. Zweitens wird die Erstellung eines qualitativ hochwertigen, insbesondere korrekt annotierten, Testdatensatzes empfohlen – auch wenn dies aufwändig sein kann. Drittens muss die Auswertung und Interpretation der Testergebnisse immer unter Berücksichtigung in der Argumentation der geforderten Signifikanz erfolgen.
Fazit
Qualitätssicherung und insbesondere Testen spielt im Kontext datengetriebener Modelle eine besonders wichtige Rolle, um Vertrauen in das Modell selbst zu gewinnen, aber auch in das System, in welchem das Modell ausgeführt wird. In einem KI-basierten System wird es immer schwieriger zu garantieren, dass alle möglichen Fehlverhalten hinreichend unwahrscheinlich sind. Assurance Cases definieren systematisch den Zusammenhang zwischen bestimmten Qualitätssicherungsmaßnahmen und einem Qualitätsziel über eine Argumentationskette.
Im vorliegenden Artikel haben wir anhand eines Anwendungsbeispiels acht Herausforderungen und Empfehlungen für die Absicherung datengetriebener Modelle mit Assurance Cases diskutiert. Dies erfordert ein hohes Maß an Interdisziplinarität:
- Kompetenzen im Bereich Safety Engineering sind nötig, um sicherzustellen, dass Assurance Cases vom Ziel bis zu den Evidenzen sauber definiert wurden, d. h., die Argumentation zur Zielerreichung stichhaltig aufgebaut und Risiken entsprechend realistisch abgeschätzt sowie behandelt wurden.
- Kompetenzen im Bereich Machine Learning und KI sind nötig, um die richtigen Argumente im Assurance Case hinsichtlich datengetriebener Modelle zu finden, wie z. B. Metriken zur Bewertung von Modelleigenschaften oder geeignete Testverfahren und -strategien.
- Kompetenzen im Bereich Empirie und Statistik sind nötig, um Qualitätssicherungsmaßnahmen so zu entwerfen und auszuwerten, dass aus ihren Resultaten stichhaltige Evidenzen entstehen. Dies beinhaltet unter anderem die Auswahl statistischer Methoden sowie Maßnahmen zur Sicherstellung repräsentativer Testdaten.
- Kompetenzen aus der Anwendungsdomäne sind nötig, um den Anwendungsfall realistisch im Assurance Case abzubilden, d. h., die Argumentation im Kontext des Anwendungsfalls inhaltlich aufzubauen und zu überprüfen.
Das Zusammenspiel dieser Kompetenzen stellt in der Praxis eine große Herausforderung dar, da das Vorwissen und die Hintergründe von Personen aus diesen vier Bereichen grundverschieden sind und zunächst eine "gemeinsame Sprache" etabliert werden muss.
Bevor datengetriebene Modelle breite Anwendung insbesondere in kritischen sicherheitsrelevanten Bereichen finden, sind allerdings noch einige offene Probleme grundsätzlich anzugehen:
- Normen und Standards zur Absicherung datengetriebener Modelle müssen definiert werden. Hierzu gibt es bereits zahlreiche Initiativen, wie z. B. die UL4600, die sich mit den notwendigen Inhalten der Assurance Cases autonomer Systeme beschäftigt, oder eine DKE-Gruppe, die Anwendungsregeln für vertrauenswürdige kognitive Systeme definiert [10].
- Der Umgang mit und die Absicherung von selbstlernenden Systemen in kritischen sicherheitsrelevanten Bereichen sollte adressiert werden. Da Modelle zur Laufzeit selbst lernen und sich entsprechend anpassen können, ist z. B. eine kontinuierliche Überwachung der Funktionsweise notwendig.
- Verfahren und Architekturen zur zusätzlichen Absicherung einer KI-Komponente zur Laufzeit sollten die Absicherung zur Entwicklungszeit komplementieren. Hier gibt es bereits Ansätze für die Bewertung der Unsicherheiten einer KI-basierten Entscheidung zur Laufzeit, wie z. B. Uncertainty-Wrapper-Architekturen [7], Dynamic Risk Management [11] oder auch Safety-Supervisor-Architekturen [12].
- Ein integrierter Entwicklungs- und Wartungsprozess für KI-Komponenten sollte definiert werden. Als Basis können einerseits bereits weit verbreitete Prozesse für den Aufbau datengetriebener Modelle, wie z. B. CRISP-DM [13], dienen. Andererseits gibt es im Bereich Software Engineering bereits weit verbreitete Entwicklungs- und Wartungsprozesse, wie agile Verfahren und DevOps-Ansätze, die die Entwicklung und den Betrieb von softwarebasierten Systemen näher zusammenbringen.
- Generell sind Muster für Assurance Cases für gängige Anwendungsbereiche wünschenswert, um den Aufwand für die Absicherung zu reduzieren. In den Forschungsprojekten PEGASUS und dem Nachfolgeprojekt V&V-Methoden wird z. B. an einem Referenz-Assurance-Case für die Domäne Automotive speziell in Bezug auf Testen gearbeitet [14].
Lassen sich mit dem heutigen Stand der Forschung also KI-basierte Systeme absichern? Schlussendlich kommt es auf die Ziele in einem entsprechenden Assurance Case an. Je nachdem, wie hoch oder niedrig diese gesteckt sind, lässt sich unter Beachtung unserer Empfehlungen auch heute schon eine überzeugende Argumentation aufbauen. In Zukunft wird sich zeigen, wie stark datengetriebene Modelle in kritischen sicherheitsrelevanten Bereichen tatsächlich in der Praxis verwendet werden. Dies hängt auch davon ab, inwieweit sich – basierend auf Best Practices – effiziente Prozesse und Architekturen für die Absicherung KI-basierter Systeme etablieren.
Danksagung: Teile der hier dargestellten Arbeiten sind im Kontext des MIND-Projektes entstanden und wurden durch das Land Rheinland-Pfalz gefördert.
- Dr. M. Kläs, Dr. A. Jedlitschka: Maschinelles Lernen und KI – warum tun wir uns im Engineering schwer damit?
- Goal Structuring Notation
- Claims Arguments Evidence
- Structured Assurance Case Metamodel
- ISO 5006: 2017-04
- BG RCI: Sicht an Erdbaumaschinen
- M. Kläs, L. Sembach: Uncertainty Wrappers for Data-driven Models - Increase the Transparency of AI/ML-based Models through Enrichment with Dependable Situation-aware Uncertainty Estimates, Second International Workshop on Artificial Intelligence Safety Engineering (WAISE 2019), Turku, Finland, 2019
- M. Kläs, A. M. Vollmer: Uncertainty in Machine Learning Applications – A Practice-Driven Classification of Uncertainty, First International Workshop on Artificial Intelligence Safety Engineering (WAISE 2018), Västerås, Sweden, 2018
- J. M. Zhang, M. Harman, L. Ma & Y. Liu: Machine learning testing: Survey, landscapes and horizons. arXiv preprint arXiv:1906.10742, 2019
- DKE: Referenzmodell für eine vertrauenswürdige KI: Erarbeitung einer neuen VDE-Anwendungsregel
- M. Trapp, D. Schneider, G. Weiss: Towards Safety-Awareness and Dynamic Safety Management (EDCC 2018), 2018
- P. Feth, D. Schneider, R. Adler: A Conceptual Safety Supervisor Definition and Evaluation Framework for Autonomous Systems. SAFECOMP 2017: 135-148
- Wikipedia: Cross-industry standard process for data mining
- Pegasusprojekt







