




Hochverfügbarkeit und Downtime: Metriken

Die Erwartungen an die Verfügbarkeit von IT-Systemen steigen nach wie vor. Um eine geeigenete Strategie zu entwerfen, sind jedoch zunächst die Anforderungen zu bestimmen. Dieser Artikel soll hierfür das Grundwissen an die Hand geben. Nach einigen Definitionen folgen Kennzahlen und Metriken zur Berechnung der Systemverfügbarkeit sowie Verfahren zur Bedarfs- und Kostenanalyse.
Dies ist der zweite Teil einer Artikelserie. Der vorige Artikel befasst sich mit Hochverfügbarkeit und Downtime: Eine Einführung.
Die Verfügbarkeit eines Systems oder einer Systemkomponente ist definiert als prozentualer Zeitanteil, in dem dieses System bzw. die Komponente fehlerfrei funktioniert. Verfügbarkeit ist also der Grad, zu dem ein Dienst oder eine Applikation jene Funktionalität für den Anwender liefert, für die er bestimmt ist. Der Grad der Verfügbarkeit ist ein wichtiger Messwert für IT-Umgebungen.
Verfügbarkeit von Daten und Anwendungen: RTO und RPO
Zu unterscheiden ist zwischen der Datenverfügbarkeit (kein oder nur geringer Datenverlust) und der Anwendungsverfügbarkeit (keine oder nur geringe Ausfallzeiten). Zwei wichtige Aspekte sind daher:
- Recovery Point Objective (RPO) - Wie hoch darf der maximale Datenverlust sein?
- Recovery Time Objective (RTO) - Wie lange darf ein IT-System maximal ausfallen?
Unter RPO versteht man den Datenverlust, der für eine Anwendung maximal tolerierbar ist. Während manche Geschäftsprozesse einen Tag Datenverlust recht gut verkraften können, sind andere recht anspruchsvoll: Daten zu Spielständen sind möglicherweise weniger zu schützen, Daten zu Banküberweisungen oder Börsengeschäften dagegen müssen stets bis zur letzten Transaktion wiederhergestellt werden können.
Als RTO wird die maximale Zeitdauer bezeichnet, während der eine Anwendung im schlechtesten Fall nicht verfügbar sein darf.
Komponenten und Verfügbarkeit: Zustände
Eine Komponente kann sich in den Zuständen verfügbar (funktionstüchtig) oder ausgefallen (nicht funktionstüchtig) befinden. Eine Komponente wird im ausgefallenen Zustand im Regelfall repariert, damit das System wieder verfügbar wird. Die Zeit, während der das System ausgefallen ist, wird daher auch als Reparaturzeit (auch TTR, Time To Repair) bezeichnet. Die Zeit, in der das System verfügbar ist, wird als die "Zeit zwischen den Ausfällen" (auch TBF, Time Between Failure) bezeichnet.
Kennzahlen der Systemverfügbarkeit: MTBF und MTTR
Kennzahlen dienen der Bewertung der Systemverfügbarkeit. Wichtige Kenngrößen der Verfügbarkeit sind:
- Mean Time Between Failure (MTBF) - Mittlere ausfallfreie Zeit eines Systems
- Mean Time to Repair (MTTR) - Mittlere Dauer für die Wiederherstellung nach einem Ausfall
Oft wird bei der Berechnung von Kennzahlen nur die Hardware in den Blick genommen. Sofern Hochverfügbarkeit eine Anforderung an ein System ist, müssen jedoch alle Komponenten beachtet werden. Ein funktionsfähiges Rechnersystem erfüllt seinen Zweck nicht, wenn die Applikation nicht läuft, das Netzwerk ausgefallen ist oder ein Benutzer versehentlich Daten in fehlerhafter Weise verändert hat. Daher muss das Gesamtsystem inklusive all seiner Komponenten betrachtet werden. Für jede dieser Komponenten muss gelten, dass sie keinen Single Point of Failure (SPof) aufweist und dass beteiligte Komponenten fehlertolerant reagieren.
Ausfälle sind zeitlich nicht gleichverteilt, d. h. die Zeiträume zwischen zwei Fehlern sind ungleich. Ist ein System neu, so ist die Wahrscheinlichkeit eines Ausfalles recht hoch. Man spricht von den so genannten Frühausfällen. Danach kommt die Phase der statistischen Ausfälle, die durch die angegebene Gleichung beschrieben wird. Bei einem hohen Alter des Systems kommt es durch Alterung und Verschleiß erneut vermehrt zu Ausfällen <link betrieb/verfuegbarkeit/hochverfuegbarkeit-und-downtime-metriken.html#c13017 - internal-link "Interner Link">[3]</link>.
Aus den in Tabelle 2 genannten Werten kann man nun die durchschnittliche Zeit bis zum nächsten Ausfall (MTBF, Mean Time Between Failure) berechnen.
Legen wir die Messwerte aus Tabelle 2 zu Grunde, so ergibt sich:
MTBF = 1980h / 9 = 220h
Ebenso berechnet sich die durchschnittliche Reparaturzeit (MTTR, Mean Time To Repair):
MTTR = 24,5h / 9 = 2,72h = 2h 43mTabelle 1: Zyklus der Systemzustände
Mathematische Grundlagen
Grundlagen zur Ermittlung typischer Metriken der Verfügbarkeit sind also Time Between Failure (TBF) und Time To Repair (TTR). Im Zeitverlauf der Systemzustände setzt sich ein Zyklus aus einer Folge von TTF und TTR zusammen.
Ein Beispiel: Nach 120 Betriebsstunden fällt ein neu erworbener Rechner aus. Die Fehlersuche, Beschaffung von Ersatzteilen und die Reparatur erfordern zwei Stunden. Danach läuft der Rechner 528 Stunden problemlos bis er erneut ausfällt. Die Reparatur benötigt 5 Stunden. Weitere 288 Stunden später fällt der Rechner ein weiteres Mal aus, ist dieses Mal schon nach einer halben Stunde einsatzbereit. TBF und TTR stellen sich dann wie in Tabelle 1 dar.

Summiert man die Zeiten, in denen die Komponente verfügbar ist, über einen genügend langen Zeitraum auf und bildet hiervon das arithmetische Mittel, kann man die durchschnittliche Verfügbarkeitsdauer (auch MTBF, Mean Time Between Failure) angeben. Das gleiche gilt für die mittlere Dauer der Ausfallzeit (MTTR, Mean Time to Repair). Betrachten wir nun einige Kennzahlen etwas genauer. Für die Verfügbarkeit V gilt:
V = MTBF / MTBFD + MTTR
Für die Nicht-Verfügbarkeit N gilt:
N = MTTR / MTBF + MTTR
Damit ergibt sich für MTTR:
MTTR = MTBF * 1 - V / V
Die (im Mittel) erwartete Zahl von Ausfällen wird mit Lambda (Ausfallrate) beschrieben:
λ = = 1 / MTBF
ERROR: Content Element with uid "13054" and type "gridelements_pi1" has no rendering definition!
Setzt man die MTBF in Beziehung zur Gesamtbetriebszeit, so kann man die Wahrscheinlichkeit berechnen, dass dieses System verfügbar ist:
V = MTBF/(MTBF + MTTR) = 220h /(220h + 2,72h) = 98,78%
Die Wahrscheinlichkeit, dass das System nicht verfügbar ist, berechnet sich hier folgendermaßen:
N = MTTR /(MTBF + MTTR) = 2,72h /(220h + 2,72h) = 1,22%
Die bisherigen Betrachtungen gelten für eine Komponente. Möchte man die Verfügbarkeit eines Systems angeben, kennt aber nur die Verfügbarkeit der Einzelkomponenten, lässt sich die Gesamtverfügbarkeit nach folgenden Regeln berechnen, die jenen der Serien- bzw. Parallelschaltung entsprechen.
Berechnung der Systemverfügbarkeit

Möchte man die Verfügbarkeit eines Gesamtsystems angeben, kennt aber nur die Verfügbarkeit der Einzelkomponenten, kann die Gesamtverfügbarkeit nach den Regeln der Serien- und Parallelschaltung berechnet werden. Abhängige und redundante Komponenten können hierbei in Ersatzschaltbildern dargestellt werden.
Serienschaltung
Eine Serienschaltung verschaltet abhängige Komponenten. Das System ist nur dann verfügbar, wenn alle Einzelkomponenten verfügbar sind. Ein Rechner ist z. B. nur dann verfügbar, wenn alle betriebsrelevanten Komponenten wie CPU, Speicher und Netzteil verfügbar sind. Das Ersatzschaltbild für eine Serienschaltung ist in Abb.3 dargestellt.
Die Gesamtverfügbarkeit eines Systems, das aus in Serienschaltung angeordneten Komponenten besteht, wird durch die Multiplikation der Einzelverfügbarkeiten berechnet. Sind die Ausfallzeiten Ni der Komponenten darüber hinaus sehr klein, lässt sich die Gesamtausfallzeit auch als Summe der Ausfallzeiten der Einzelkomponenten angeben. Die Ausfallrate ist dann die Summe der Ausfallraten der Einzelkomponenten.
Es gilt:
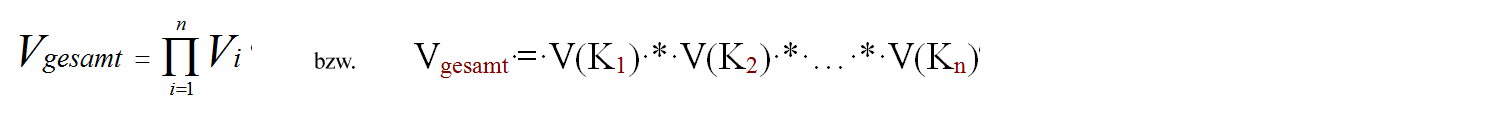
wobei V(Kn) die Verfügbarkeit der Komponenten n beschreibt.
Für N << 1 gilt:
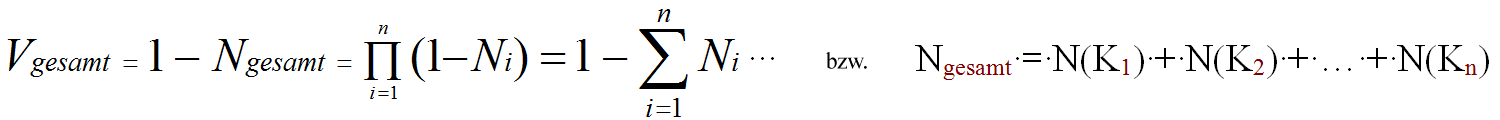

wobei N(Kn) die Nicht-Verfügbarkeit der Komponenten n beschreibt.
Die Fehlerquote eines Systems, das aus mehreren Elementen besteht, steigt mit der Zahl der Elemente. Betrachtet man hierfür nur die für die Sicherheit relevanten Elemente, so arbeitet ein solches System nur dann sicher, wenn alle Einzelelemente richtig arbeiten. Damit sind Ausfallzeit und Ausfallwahrscheinlichkeit des Gesamtsystems wesentlich größer als jene einer Einzelkomponente.
Parallelschaltung
In einer Parallelschaltung sind die Komponenten redundant angeordnet. Das System ist verfügbar, solange mindestens eine von mehreren Komponenten verfügbar ist. Man spricht hier auch von unabhängigen Komponenten.
Die Gesamtausfallzeit in einer Parallelschaltung ergibt sich aus dem Produkt der Einzelausfallzeiten. Hieraus ergibt sich:

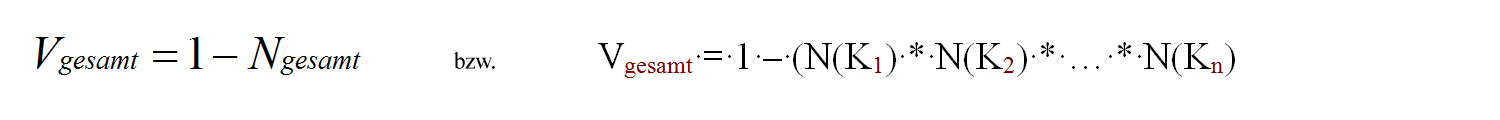
Berechnung von Ausfallwahrscheinlichkeiten des Gesamtsystems
Wie wir gesehen haben, ist die Anzahl und Anordnung der Komponenten von zentraler Bedeutung. Dieser Sachverhalt soll nun verdeutlicht werden. Angenommen, es werden zwei Komponententypen A und B in einem System eingesetzt. Komponenten des Typs A haben eine Verfügbarkeit von etwa 99,99% (etwa 53 Minuten Ausfallzeit pro Jahr). Komponenten des Typs B haben eine Verfügbarkeit von 99,9% (etwa 8,8 Stunden Ausfallzeit pro Jahr). Diese Komponenten werden in den folgenden drei Beispielen in unterschiedlicher Anzahl und Anordnung eingesetzt. Annahmen:- Komponenten des Typs A haben eine Verfügbarkeit von 99,99% (~ 53 Min Ausfall/Jahr).
- Komponenten des Typs B haben eine Verfügbarkeit von 99,9% (~ 8,8 Stunden Ausfall/Jahr).

Vgesamt = V(A) * V(B)Das heißt für die Serienschaltung der Komponenten A und B gemäß Abb.5: Geschätzte Ausfallzeit Komponente A: ~ 53 Min / Jahr
= 0,9999 * 0,999
= 0,9989001
Agesamt = 1 - Vgesamt
= 1 - 0,9989001
= 0,0010999
Geschätzte Ausfallzeit Komponente B: ~ 8.8 Std / Jahr
Geschätzte Ausfallzeit des Gesamtsystems: ~ 9.7 Std / Jahr

Vgesamt = 1 - (1 - V(A1) * V(B1)) * (1 - V(A2) * V(B2))Das heißt für die Parallelschaltung gemäß Abb.6: Geschätzte Ausfallzeit Komponente A: ~ 53 Min / Jahr
= 1 - (1 - 0,9999 * 0,999) * (1 - 0,9999 * 0,999)
= 0,99999879
Agesamt = 1 -Vgesamt
= 1 - 0,99999879
= 0,00000121
Geschätzte Ausfallzeit Komponente B: ~ 8.8 Std / Jahr
Geschätzte Ausfallzeit des Gesamtsystems: ~ 38 Sekunden / Jahr In diesem Beispiel sind nun noch jeweils die Komponenten A1 und B1 sowie A2 und B2 in Serie geschaltet. Das hat zur Folge, dass bei Ausfall der Komponente A1 der Gesamtzweig1 nicht mehr verfügbar ist. Hebt man diese Serienschaltung auf und parallelisiert auch hier, so kommt man zu Beispiel 3.

- Ausfallwahrscheinlichkeit von A1 und A2 identisch
- Ausfallwahrscheinlichkeit von B1 und B2 identisch
Vgesamt = V(Agesamt) * V(Bgesamt)Das heißt: Geschätzte Ausfallzeit Komponente A: ~ 53 Min / Jahr
= V(A)2 * V(B)2
Agesamt = 1 – V(Agesamt) * V(Bgesamt)
= 1 – (1 –V(A))2 * (1 – V(B))2
Geschätzte Ausfallzeit Komponente B: ~ 8.8 Std / Jahr
Geschätzte Ausfallzeit des Gesamtsystems: ~ 3 Sekunden / Jahr
| Formel | Berechnung Downtime | Downtime/Jahr | |
|---|---|---|---|
| Beispiel 1 |
Agesamt = 1–AA*AB |
Agesamt = 1-0,9999*0,999 = 1-0,9989001 = 0,0010999 | 9,7 Std. |
| Beispiel 2 |
Agesamt = (1-(AA1*AB1))*(1-(AA2*AB2)) |
Agesamt = (1-0,9999*0,999)* (1-0,9999*0,999) = 0,0000012098 | 38 Sek. |
| Beispiel 3 |
Agesamt = 1–AAgesamt*PBgesamt = 1-(1–AA)2*(1–AB)2 |
Agesamt = 1-(1-0,9999)2* *(1–0,999)2 = 0,0000001000 | 3 Sek. |
Verfügbarkeitsklassen
Die Verfügbarkeit von Computersystemen wird meist in "Dauer Downtime pro Jahr" gemessen und in Prozent angegeben. Die Harvard Research Group (HRG) teilt Hochverfügbarkeit in ihrer Availability Environment Classification (kurz: AEC) in 6 Klassen ein:
- Conventional (AEC-0): Funktion kann unterbrochen werden, Datenintegrität ist nicht essentiell
- Highly Reliable (AEC-1): Funktion kann unterbrochen werden, Datenintegrität muss jedoch gewährleistet sein
- High Availability (AEC-2): Funktion darf nur innerhalb festgelegter Zeiten bzw. zur Hauptbetriebszeit minimal unterbrochen werden
- Fault Resilient (AEC-3): Funktion muss innerhalb festgelegter Zeiten bzw. während der Hauptbetriebszeit ununterbrochen aufrechterhalten werden
- Fault Tolerant (AEC-4): Funktion muss ununterbrochen aufrechterhalten werden, 24*7 Betrieb (24 Stunden, 7 Tage die Woche) muss gewährleistet sein
- Disaster Tolerant (AEC-5): Funktion muss unter allen Umständen verfügbar sein
| Verfügbarkeits-Klasse | Bezeichnung | Verfügbarkeit in Prozent | Downtime pro Jahr |
|---|---|---|---|
| 2 | Stabil | 99,0 | 3,7 Tage |
| 3 | Verfügbar | 99,9 | 8,8 Stunden |
| 4 | Hochverfügbar | 99,99 | 52,2 Minuten |
| 5 | Fehlerunempfindlich | 99,999 | 5,3 Minuten |
| 6 | Fehlertolerant | 99,9999 | 32 Sekunden |
| 7 | Fehlerresistent | 99,999999 | 3 Sekunden |
Ausfallkosten und Aufwände für Verfügbarkeit
")
Verfahren zur Kostenanalyse
- Betroffene Anwendungen?
- Entstehende Einnahmeverluste je Ausfall-Minute?
- Entstehende Produktionsausfälle entstehen je Ausfall-Minute?
- Kosten für Personal, Räumlichkeiten usw. je Minute?
- Länge der Ausfallzeit?
- Verlust von Kunden?
- Mögliche Rechtskosten und Regressansprüche von Kunden und Geschäftspartnern?
- Entstehen Datenverluste? Falls ja: Mit welchen Auswirkungen?
| Geschäftsfeld | Kosten je Stunde Ausfallzeit |
|---|---|
| Airline Reservation Centers | 67.000$ – 112.000$ |
| Bank ATM Service Fees | 12.000$ – 17-000$ |
| Brokerage House (Stock) | 5.600.000$ – 7.300.000 $ |
| Catalog Sales Centers | 60.000$ – 120.000$ |
| Package Shipping | 28.000$ – 32.000$ |
| Credit Card / Sales Authorization | 2.200.000$ – 3.100.000$ |
| Pay-per-View Television | 67.000$ – 112.000$ |
| Teleticket Sales | 56.000$ – 82.000$ |

Die Bedarfsanalyse
In der Bestandsanalyse wird erfasst, welche Anwendungen wo im Unternehmen implementiert sind, auf welchen Plattformen diese laufen und welche Ressourcen benötigt werden, um ihren reibungslosen Betrieb zu gewährleisten. Diese Verfahrensweise garantiert, dass wirklich alle Organisationsebenen und Abteilungen eines Unternehmens bzw. des betreffenden Geschäftsbereiches vom High End-Server über die Desktops der Mitarbeiter bis hin zu den Laptops des Außendienstes in die Disaster Recovery-Strategie miteinbezogen werden. Gefahrenanalyse
Die IT-Umgebung sollte genau auf alle potenziellen Schwachstellen hin untersucht werden. Welche Gründe es für einen Daten-GAU geben kann, wurde bereits beschrieben. Eine individuelle Analyse der Worst-Case Szenarien im eigenen Unternehmen ist hilfreich. Risikoanalyse
Der Einfluss eines Systemausfalls auf das Weiterlaufen der Geschäftsprozesse ist immens wichtig. Es macht selbstverständlich einen großen Unterschied, ob eine Anwendung, die nur unregelmäßig benötigt wird und nur zeit-unkritische Prozesse unterstützt, oder ob eine geschäftskritische Anwendung wie das Kassensystem eines Kaufhauses ausfällt. Wurden Risiken für das Unternehmen und dessen IT-Systeme identifiziert, müssen auch die individuellen Risiken für jede einzelne Anwendung analysiert werden. Hieraus lässt sich ableiten, welche Geschäftsprozesse besser gesichert werden müssen und welche bereits mit minimalem Aufwand ausreichend geschützt werden können. Kostenanalyse
Aus den gewonnenen Erkenntnissen über den individuellen Sicherheitsbedarf eines Unternehmens lässt sich berechnen, welche Kosten im Rahmen verschiedener Disaster Recovery-Strategien einzelner Anwendungen entstehen können. Break-even-Analyse
Die durch die angenommene und geschätzte Ausfallwahrscheinlichkeit und -dauer gewichteten Kosten für einen Systemausfall müssen abschließend den Kosten einzelner Maßnahmen zur Absicherung gegen Systemausfälle gegenübergestellt werden. So kann der Break-even-Point zwischen jährlichen, durch Systemausfälle verursachten Kosten und jährlichen Kosten zur Sicherung der Systemlandschaft gegen Ausfälle identifiziert werden. Neben diesem können dann auch weiche Faktoren wie potenzielle Imageverluste und Verlust der Kundenbindung zur Bewertung herangezogen werden. Wichtig ist nicht nur, wie viel Ausfallzeit ein Unternehmen verkraften kann, sondern ebenso, wie hoch der Datenverlust maximal sein darf. Manche Unternehmen kommen mit einem einfachen Backup aus. Wird damit täglich gesichert, gehen maximal die Änderungen des letzten Arbeitstages vor dem Ausfall verloren. Banken und Finanzdienstleister dagegen müssen in einigen Geschäftsfeldern Datenverluste gänzlich ausschließen können. Hier werden häufig Technologien wie synchrone Replikation über große Reichweiten hinweg eingesetzt. Dies bietet nicht nur Schutz vor Ausfällen einer einzelnen Speicherkomponente. Auch bei Verlust eines ganzen Rechenzentrums sind alle Daten auf dem entfernten Spiegel gesichert. Es gibt spezielle Anforderungen in manchen Geschäftszweigen, die dazu führen, dass in diesen Umgebungen das Gesamtsystem heruntergefahren wird, sobald das Spiegelsystem nicht mehr verfügbar ist. Das klingt zunächst merkwürdig, hat jedoch einen Sinn: Ein möglicher Datenverlust würde schwerer wiegen und könnte teurer werden als eine vorübergehende Downtime. Abschließende Bewertung
Zwei Faktoren bilden wichtige Eckpunkte der Bewertung: Die Kenngröße Recovery Point Objective (RPO) für den möglichen Datenverlust sowie Recovery Time Objective (RTO) für die Ausfallzeit. Letztere ist identisch mit der MTTR (s. o.). Auch innerhalb eines Unternehmens können unterschiedliche Anforderungen an RPO und MTTR bestehen. Ein Datei- und Print-Server muss im Allgemeinen lange nicht so gut vor Systemausfällen und Datenverlust geschützt sein wie ein Online-Bestellsystem. RPO und MTTR können auch völlig unterschiedlich gewichtet werden. Ein Kassensystem kann sich keinen Datenverlust erlauben und erfordert daher einen sehr geringen RPO-Wert, muss aber vielleicht nicht zwingend sofort nach einem Ausfall wieder in Betrieb gehen, wenn etwa außerhalb der Öffnungszeiten nicht auf die Daten zugegriffen wird. In diesem Fall kann die MTTR recht hoch sein, ohne dass dies Auswirkungen auf die Geschäfte des Unternehmens hat. Auf der anderen Seite ist ein Webserver gegenüber Datenverlusten relativ tolerant, muss aber konstant verfügbar sein. Daraus folgt für die Anwendung ein relativ hoher RPO, während die MTTR sehr niedrig sein muss. Die abschließende Bewertung sollte auch eine Prüfung der Effizienz bereits vorhandener Hochverfügbarkeits- und Disaster Recovery-Lösungen einschließen, deren Ergebnisse mit den Anforderungen verglichen werden. So lässt sich genau feststellen, wo Verbesserungen gemacht werden können. Oft können Neuinvestitionen in kostspielige Hardware durch eine effiziente Nutzung der bestehenden Ressourcen vermieden werden.
Resümee
- Anonym, DIN 66201: Prozessrechensysteme, Beuth Verlag GmbH, Berlin 1981
- W. A. Halang, R. Konakovsky: Sicherheitsgerichtete Echtzeitsysteme, 1. Auflage, München 1999, Oldenbourg Verlag
- G. Färber: Prozessrechentechnik, 3. Auflage, Berlin 1994, Springer Verlag
- Downtime-Calculator
Publikationen
- Oracle 12c New Features: Inklusive Release 2
- Der Oracle DBA: Handbuch für die Administration der Oracle Database 12c
- Oracle 11g. Neue Features für Administratoren und Entwickler
- Oracle 10g Hochverfügbarkeit. Die ausfallsichere Datenbank mit RAC, Data Guard und Flashback Edition Oracle






